Stable baselines 3 - 1st steps
installation, 1st experimentations
- What is stable baselines 3 (sb3)
- My installation
- SB3 tutorials
- Issues and fix
- Stable baselines 3 user guide
What is stable baselines 3 (sb3)
I have just read about this new release. This is a complete rewrite of stable baselines 2, without any reference to tensorflow, and based on pytorch (>1.4+).
There is a lot of running implementations of RL algorithms, based on gym. A very good introduction in this blog entry
Stable-Baselines3: Reliable Reinforcement Learning Implementations | Antonin Raffin | Homepage
Links
-
GitHub repository: https://github.com/DLR-RM/stable-baselines3
-
Documentation: https://stable-baselines3.readthedocs.io/
-
RL Baselines3 Zoo: https://github.com/DLR-RM/rl-baselines3-zoo
-
Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
-
RL Tutorial: https://github.com/araffin/rl-tutorial-jnrr19
Standard installation
conda create --name stablebaselines3 python=3.7
conda activate stablebaselines3
pip install stable-baselines3[extra]
conda install -c conda-forge jupyter_contrib_nbextensions
conda install nb_conda
!conda list
import gym
from stable_baselines3 import A2C
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.callbacks import CheckpointCallback, EvalCallback
# Save a checkpoint every 1000 steps
checkpoint_callback = CheckpointCallback(save_freq=5000, save_path="/home/explore/git/guillaume/stable_baselines_3/logs/",
name_prefix="rl_model")
# Evaluate the model periodically
# and auto-save the best model and evaluations
# Use a monitor wrapper to properly report episode stats
eval_env = Monitor(gym.make("LunarLander-v2"))
# Use deterministic actions for evaluation
eval_callback = EvalCallback(eval_env, best_model_save_path="/home/explore/git/guillaume/stable_baselines_3/logs/",
log_path="/home/explore/git/guillaume/stable_baselines_3/logs/", eval_freq=2000,
deterministic=True, render=False)
# Train an agent using A2C on LunarLander-v2
model = A2C("MlpPolicy", "LunarLander-v2", verbose=1)
model.learn(total_timesteps=20000, callback=[checkpoint_callback, eval_callback])
# Retrieve and reset the environment
env = model.get_env()
obs = env.reset()
# Query the agent (stochastic action here)
action, _ = model.predict(obs, deterministic=False)
CUDA error: CUBLAS_STATUS_INTERNAL_ERROR
Downgrade pytorch to 1.7.1
to avoid RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling cublasCreate(handle)
pip install torch==1.7.1
RuntimeError: CUDA error: invalid device function
!nvidia-smi
CUDA version is 11.0 on my workstation.
!nvcc --version
!conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
Everything seems fine after these updates.
There is an impressive documentation associated with stable baselines 3. Quickstart
This page covers general advice about RL (where to start, which algorithm to choose, how to evaluate an algorithm, …), as well as tips and tricks when using a custom environment or implementing an RL algorithm.
Tune hyperparameters RL zoo is introduced. It contains some hyperparameter optimization.
RL evaluation We suggest you reading Deep Reinforcement Learning that Matters for a good discussion about RL evaluation.
which algorithm to choose 1st criteria is discrete vs continuous actions. And 2nd is capacity to parallelize training.
Discrete Actions
- Discrete Actions - Single Process
DQN with extensions (double DQN, prioritized replay, …) are the recommended algorithms. We notably provide QR-DQN in our contrib repo. DQN is usually slower to train (regarding wall clock time) but is the most sample efficient (because of its replay buffer).
- Discrete Actions - Multiprocessed
You should give a try to PPO or A2C.
Continuous Actions
- Continuous Actions - Single Process
Current State Of The Art (SOTA) algorithms are SAC, TD3 and TQC (available in our contrib repo). Please use the hyperparameters in the RL zoo for best results.
- Continuous Actions - Multiprocessed
Take a look at PPO or A2C. Again, don’t forget to take the hyperparameters from the RL zoo for continuous actions problems (cf Bullet envs).
Creating a custom env
multiple times there are advices about normalizing: observation and action space. A good practice is to rescale your actions to lie in [-1, 1]. This does not limit you as you can easily rescale the action inside the environment
tips and tricks to reproduce a RL paper
Reinforcement Learning Tips and Tricks — Stable Baselines3 1.1.0a1 documentation
A personal pick (by @araffin) for environments with gradual difficulty in RL with continuous actions:> > 1. Pendulum (easy to solve)
HalfCheetahBullet (medium difficulty with local minima and shaped reward)
BipedalWalkerHardcore (if it works on that one, then you can have a cookie)
in RL with discrete actions:> > 1. CartPole-v1 (easy to be better than random agent, harder to achieve maximal performance)
LunarLander
Pong (one of the easiest Atari game)
other Atari games (e.g. Breakout)
Reinforcement Learning Resources — Stable Baselines3 1.1.0a1 documentation
Stable-Baselines3 assumes that you already understand the basic concepts of Reinforcement Learning (RL).
However, if you want to learn about RL, there are several good resources to get started:
I will run these examples in 01 -hands-on.ipynb from handson_stablebaselines3

PPO with multiprocessing cartpole

Monitor training using callback
This could be useful when you want to monitor training, for instance display live learning curves in Tensorboard (or in Visdom) or save the best agent.

Atari game such as pong (A2C with 6 envt) or breakout

Here the list of valid gym atari environments: https://gym.openai.com/envs/#atari
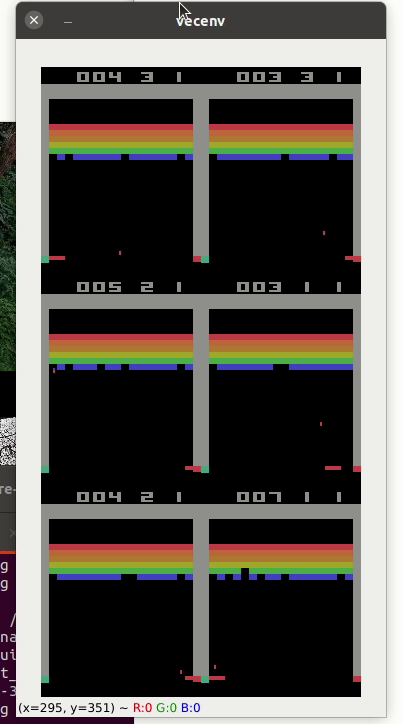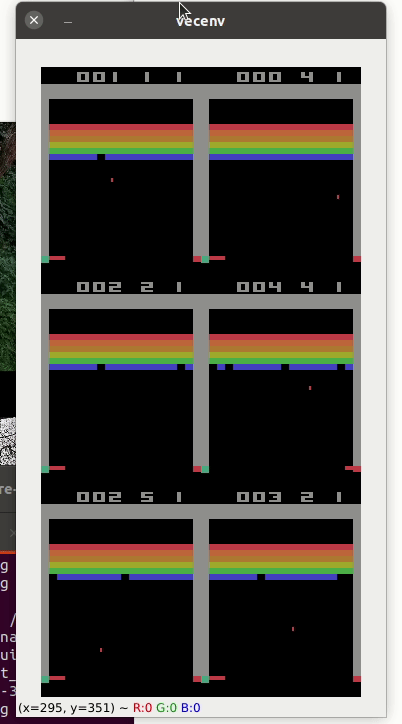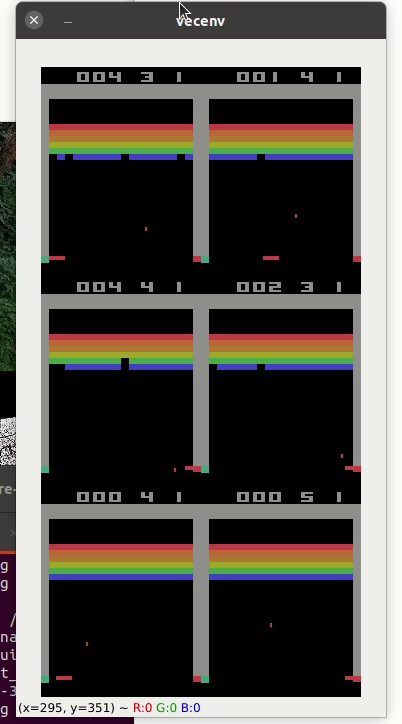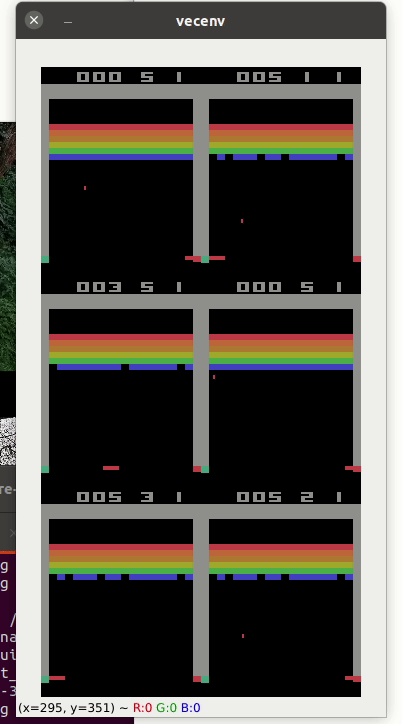
pybullet
This is a SDK to real-time collision detection and multi-physics simulation for VR, games, visual effects, robotics, machine learning etc.
https://github.com/bulletphysics/bullet3/
We need to install it: pip install pybullet
I don't have rendering capacity when playing with it. Because robotic is far from my need, I will skip on this one
Hindsight Experience Replay (HER)
using Highway-Env
installation with pip install highway-env
After 1h15m of training, some 1st results:

And after that some technical stuff such as:
- Learning Rate Schedule: start with high value and reduce it as learning goes
- Advanced Saving and Loading: how to easily create a test environment to evaluate an agent periodically, use a policy independently from a model (and how to save it, load it) and save/load a replay buffer.
- Accessing and modifying model parameters: These functions are useful when you need to e.g. evaluate large set of models with same network structure, visualize different layers of the network or modify parameters manually.
- Record a video or make a gif
Make a GIF of a Trained Agent
pip install imageio
and this time the lander is getting closer to moon but not at all between flags.
