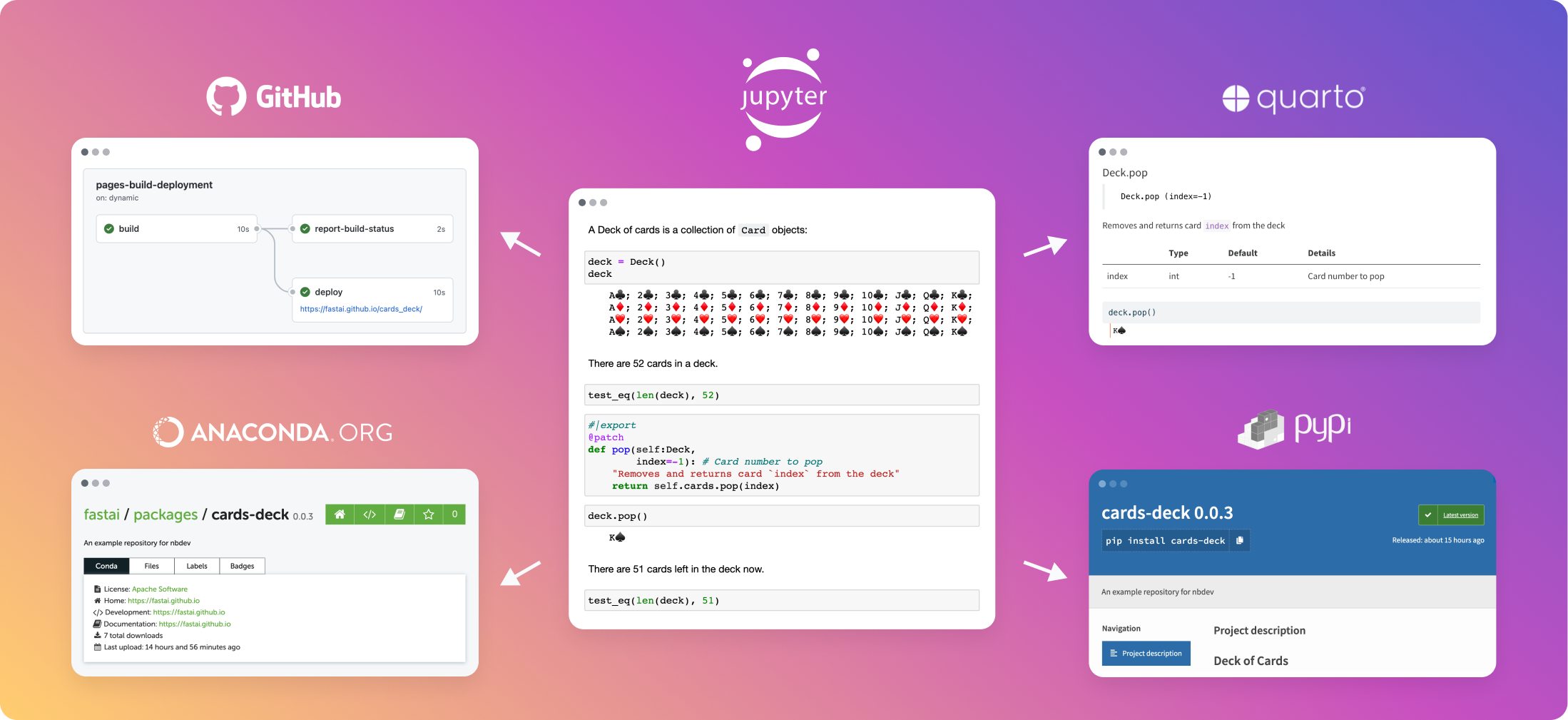
nbdev can be used from here. For example nbdev_help to display all nbdev_ commands and what it does. And more detail can be got with -h: nbdev_new -h
!{sys.prefix}/bin/nbdev_help
nbdev_bump_version Increment version in settings.ini by one
nbdev_changelog Create a CHANGELOG.md file from closed and labeled GitHub issues
nbdev_clean Clean all notebooks in `fname` to avoid merge conflicts
nbdev_conda Create a `meta.yaml` file ready to be built into a package, and optionally build and upload it
nbdev_create_config Create a config file.
nbdev_deploy Deploy docs to GitHub Pages
nbdev_docs Create Quarto docs and README.md
nbdev_export Export notebooks in `path` to Python modules
nbdev_filter A notebook filter for Quarto
nbdev_fix Create working notebook from conflicted notebook `nbname`
nbdev_help Show help for all console scripts
nbdev_install Install Quarto and the current library
nbdev_install_hooks Install Jupyter and git hooks to automatically clean, trust, and fix merge conflicts in notebooks
nbdev_install_quarto Install latest Quarto on macOS or Linux, prints instructions for Windows
nbdev_merge Git merge driver for notebooks
nbdev_migrate Convert all directives and callouts in `fname` from v1 to v2
nbdev_new Create an nbdev project.
nbdev_prepare Export, test, and clean notebooks, and render README if needed
nbdev_preview Preview docs locally
nbdev_pypi Create and upload Python package to PyPI
nbdev_quarto Create Quarto docs and README.md
nbdev_readme Render README.md from index.ipynb
nbdev_release_both Release both conda and PyPI packages
nbdev_release_gh Calls `nbdev_changelog`, lets you edit the result, then pushes to git and calls `nbdev_release_git`
nbdev_release_git Tag and create a release in GitHub for the current version
nbdev_sidebar Create sidebar.yml
nbdev_test Test in parallel notebooks matching `path`, passing along `flags`
nbdev_trust Trust notebooks matching `fname`
nbdev_update Propagate change in modules matching `fname` to notebooks that created them
nbdev_new. It is creating the structure and files such as settings.ini.
from base environment we can start jupyter notebook. It is advised to install nb_extensions (pip install jupyter_contrib_nbextensions), and activate TOC2. Open 00_core.ipynb with dataset_tools kernel. Rename 00_core.ipynb –> 00_container.ipynb
and #| prefix in notebooks as well
Jeremy explains then what are #| used by quarto and nbdev.
And for example #| hide will allow to be executed but hide in your documentation.
Actually from a single notebook, you have 3 usages: * the notebook by itself - all cells are executed, whatever are the prefix #| that you display on cells * the python file - only the cells with #| export will be published in a python file referenced as #| default_exp <name of python file>. A new file is genreated when nbdev_export is called. * the documentation - all cells are used, except the one started with #| hide. Seems to be dynamically generated (when nbdev_preview is running?). #| export are handled specifically: if you have import, nothing is displayed. If you have code, definitions and docstrings are exported, and arguments as well.
There is an easy way to describe arguments of a function.
Just make some indentation with comments such as in
def__init__(self, cle : str, # la clé du container dataset : pd.DataFrame =None, # le dataset colonnes_a_masquer : list= [], # les colonnes à masquer colonnes_a_conserver : list= [] # les colonnes qui ne seront pas transformées ):
show_doc
and we can directly see the effect of it by calling show_doc (show_doc(Container)). You can even call show_doc on code not written with nbdev, or not even written by you.
from nbdev.showdoc import*import pandas as pdshow_doc(pd.DataFrame)
/home/guillaume/miniconda/envs/dataset_tools/lib/python3.9/site-packages/fastcore/docscrape.py:225: UserWarning: Unknown section See Also
else: warn(msg)
/home/guillaume/miniconda/envs/dataset_tools/lib/python3.9/site-packages/fastcore/docscrape.py:225: UserWarning: Unknown section Examples
else: warn(msg)
Data structure also contains labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure.
Type
Default
Details
data
NoneType
None
Dict can contain Series, arrays, constants, dataclass or list-like objects. If data is a dict, column order follows insertion-order. If a dict contains Series which have an index defined, it is aligned by its index.
.. versionchanged:: 0.25.0 If data is a list of dicts, column order follows insertion-order.
index
Axes | None
None
Index to use for resulting frame. Will default to RangeIndex if no indexing information part of input data and no index provided.
columns
Axes | None
None
Column labels to use for resulting frame when data does not have them, defaulting to RangeIndex(0, 1, 2, …, n). If data contains column labels, will perform column selection instead.
dtype
Dtype | None
None
Data type to force. Only a single dtype is allowed. If None, infer.
copy
bool | None
None
Copy data from inputs. For dict data, the default of None behaves like copy=True. For DataFrame or 2d ndarray input, the default of None behaves like copy=False.
.. versionchanged:: 1.3.0
unit testing
There are some basic testing functionalty available by importing fastcore. from fastcore.test import *
With test_eq very closed to assert and test_ne closed to assert not
from fastcore.test import*show_doc(test_eq)show_doc(test_ne)
This is convenient to integrate all the unit tests that way. When you will export by running Restart & Run All, if an error is met, export won’t be done.
And one can run nbdev_test from the command line.
@patch - define method out of its class
Just by adding this import
from fastcore.utils import*
one can use
@patchdef new_method(self:myclass):pass
nbdev_export
from command line, one can run nbdev_export
or directly from jupyter, for example will be executing Restart & Run All
#| hideimport nbdev; nbdev.nbdev_export()
And we can install it to be used directly by running pip install -e .
It means that you can now import your project with
from dataset_tools.container import *
When it will be published (pypi or conda), it will be installable by calling
pip install dataset-tools
or
conda install -c fastai dataset-tools
NB: see how _ has been turned into -, and for that to happen we have to update lib_name and lib_path in settings.ini by replacing _with -
NB2: it is still confusing for me. It looks like modifying lib_path is not a good optiom.
index.ipynb
Here it is a good idea to give overview about how to use it.
By importing your library and start using it.
And it will be exported as the homepage of your lib.
Just have to decide what should land in index and what should land in module page.
This is a quarto webserver. The 1st time you launch it it will install quarto for you. On ubuntu this is a standard package so it will be updated regularly.
from getpass import getpass!echo {getpass()} | sudo -S apt-cache show quarto
········
[sudo] password for guillaume: Package: quarto
Status: install ok installed
Priority: optional
Section: user/text
Installed-Size: 242759
Maintainer: RStudio, PBC <quarto@rstudio.org>
Architecture: amd64
Version: 1.1.189
Description: Quarto is an academic, scientific, and technical publishing system built on Pandoc.
Description-md5: 516c872f9c3577457bbd01eac38f8130
Homepage: https://github.com/quarto-dev/quarto-cli
nbdev_test
As mentionned earlier, one can run nbdev_test to execute all tests in all notebooks.
If it fails, Hamel has shared his dev workflow. He runs Restart kernel & run All, and use %debug magic command to enter debug mode.
You then have access to all ipdb commands such as h for help, p var to print content of var, w for stacktraces
%debug
> /tmp/ipykernel_2453/349085080.py(1)<cell line: 1>()
----> 1 show_doc(test_eq)
ipdb> h
Documented commands (type help <topic>):
========================================
EOF commands enable ll pp s until
a condition exit longlist psource skip_hidden up
alias cont h n q skip_predicates w
args context help next quit source whatis
b continue ignore p r step where
break d interact pdef restart tbreak
bt debug j pdoc return u
c disable jump pfile retval unalias
cl display l pinfo run undisplay
clear down list pinfo2 rv unt
Miscellaneous help topics:
==========================
exec pdb
ipdb> q
Golden rule: don’t mix imports and code
For a reason it is asked not to mix cells with imports and code.
I am not sure what is the core reason for that. Something due to show_doc or doc generation?
During my tests, I have seen something complaining about it after running nbdev_export or nbdev_test but cannot reproduce that. Hmmm
nbdev_clean
Just to remove unnecessary metadata in ipynb files.
/home/guillaume/miniconda/envs/dataset_tools/lib/python3.9/site-packages/ghapi/core.py:99: UserWarning: Neither GITHUB_TOKEN nor GITHUB_JWT_TOKEN found: running as unauthenticatedelse: warn('Neither GITHUB_TOKEN nor GITHUB_JWT_TOKEN found: running as unauthenticated')Could not access repo: janus/nbdev_gitlab to find your default branch -`main` assumed.Edit`settings.ini` if this is incorrect.In the future, you can allow nbdev to see private repos by setting the environment variable GITHUB_TOKEN as described here:https://nbdev.fast.ai/cli.html#Using-nbdev_new-with-private-reposrepo = nbdev_gitlab # Automatically inferred from gituser = janus # Automatically inferred from gitauthor = guillaume # Automatically inferred from gitauthor_email = guillaume.ramelet@michelin.com # Automatically inferred from git# Please enter a value for descriptiondescription = This is the smallest project to make nbdev working with gitlabsettings.ini created./home/guillaume/miniconda/envs/dataset_tools/lib/python3.9/site-packages/ghapi/core.py:99: UserWarning: Neither GITHUB_TOKEN nor GITHUB_JWT_TOKEN found: running as unauthenticatedelse: warn('Neither GITHUB_TOKEN nor GITHUB_JWT_TOKEN found: running as unauthenticated')pandoc-o README.mdto: gfm+footnotes+tex_math_dollars-yaml_metadata_blockstandalone: truedefault-image-extension: pngmetadatadescription: This is the smallest project to make nbdev working with gitlabtitle: nbdev_gitlabOutput created: _docs/README.md
- set company_name = acme
- set doc_path = public
- set branch = main instead of master
- doc_host = https://%(user)s.pages.gitlab.%(company_name)s.com/
- git_url = https://gitlab.%(company_name)s.com/%(user)s/%(repo)s
- doc_baseurl = /%(repo)s
change in _quarto.yml
nothing to be done with nbdev > v2.3.3
create .gitlab-ci.yml –> build/publish documentation, push to artifactory
With gitlab you have a nice editor to edit pipelines (CI lint)
One way to debug is to insert sleep xx and then click debug.
You then have access to your docker image.
default:image:'docker.artifactory.michelin.com/michelin/hub/ubuntu20.04:bib-1.1'tags:- k8sinterruptible: trueretry:max: 2when:- runner_system_failure- stuck_or_timeout_failure# Functions that should be executed before the build script is runbefore_script:- apt -y install wget- wget "https://github.com/quarto-dev/quarto-cli/releases/download/v1.1.189/quarto-1.1.189-linux-amd64.deb"- dpkg -i quarto-1.1.189-linux-amd64.deb- apt -y install python3-pip- wget --no-check-certificate--content-disposition-O- https://raw.githubusercontent.com/castorfou/guillaume_blog/master/files/setup_wsl_08_pip.sh |bash- pip3 install nbdev- nbdev_installstages:- test- build_doc- build- deploy_artifactorytests:stage: testscript:- nbdev_testpages:stage: build_docscript:- nbdev_docsartifacts:paths:# The folder that contains the files to be exposed at the Page URL- publicrules:# This ensures that only pushes to the default branch will trigger# a pages deploy- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCHwheel:stage: buildscript:- mkdir -p public- echo "Build wheel with python version `python3--version`:"- pip install -U setuptools wheel pydnx_packaging- pip install -e .- python3 setup.py bdist_wheel- mkdir -p packages &&mv dist/* packages/artifacts:when: alwayspaths:- packages/publish:stage: deploy_artifactorydependencies:- wheelonly:- tagsscript:# create credential config file->if[-f'.pypirc'];thenecho"Information: .pypirc file is not mandatory anymore."&&cp .pypirc ~/elseecho"[distutils] index-servers = local [local] repository: https://artifactory.michelin.com/api/pypi/pypi username: fm00884 password: <don't even think about it>"> ~/.pypircfi- pip install -U twine- pip index versions nbdev_gitlab ||true- echo 'If the "twine upload" command below failed with a 403 status code, please check that the version is not already uploaded on artifactory (see versions of nbdev_git above).'- twine upload --verbose-r local packages/*
commit to gitlab
nbdev_preparerm-rf index_filesnbdev_docs#optionnal if nbdev_preview was usednbdev_proc_nbsgit diffgit statusgit add -Agit commit -am'<proper comment>'git push
not exported, not displayed in doc, executed in jupyter
Some examples:
imports
imports that I need for development that I don’t need in my lib
here it will be used later in internal tests (and will be executed with nbdev_test)
#| hide#not exported, not displayed in doc, executed in jupyter# I need this to develop but not to be found in my lib (actuelly my lib should not depend on nbdev)from nbdev.showdoc import*import tempfilefrom sklearn.datasets import load_diabetes
tests
some internal tests that I don’t wand in doc
#| hidewith tempfile.TemporaryDirectory(dir=root_data) as tmpdirname: temp_mixpath = MixPath(tmpdirname.split(os.sep)[-1])print(temp_mixpath, temp_mixpath.OBF_DIRECTORY)
or
#| hidetest_eq(ml25625,MixPath('25625'))
toc
some markdown that will appear in jupyter’s TOC
but not in doc because I have some export after that
#| hide
### DatasetObf.get_dataset_initial_filtré
export module
at the end of notebook
here to have an entry in TOC
#| hide
# Export module
and here to export notebook code when restart kernel and run all
#| hideimport nbdev; nbdev.nbdev_export()
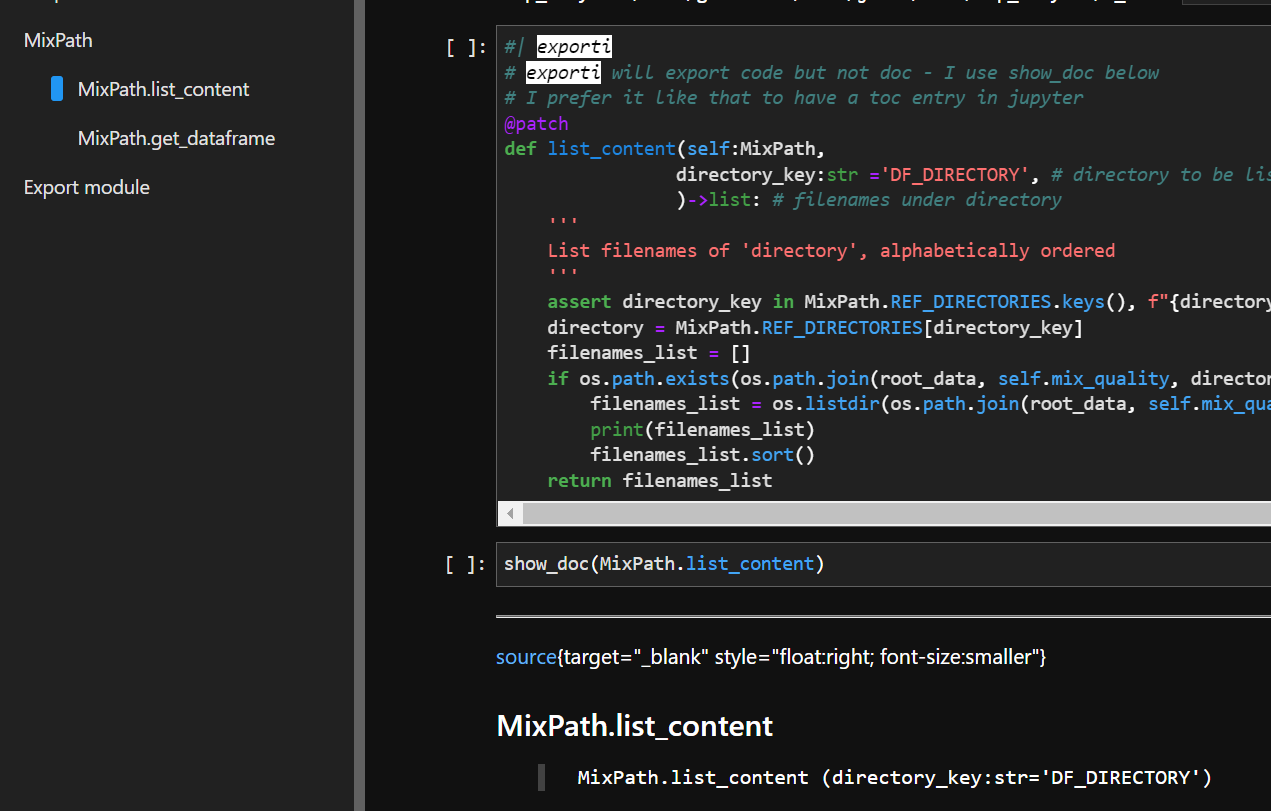
#| exporti - used in combination of @patch and show_doc
exporti will export code but not doc - I use show_doc below
without exporti I would have 2 entries in doc
I prefer it like that to have a toc entry in jupyter
And only with methods from a class. (otherwise it won’t be exposed)
pip install -U nbdevrm _quarto.ymlnbdev_new# reintegrate entries in settings.ini that could have been changed such as requirements, dev_requirements, clean_ids
Seem has fixed it. Culprit was in execnb. It will be integrated in release 0.1.5. Meanwhile I can fix it by running pip install git+https://github.com/fastai/execnb.git